
 Widok zawartości stron
Widok zawartości stron
Nawigacja okruszkowa
Widok zawartości stron
Widok zawartości stron
Elektroniczny korpus literatury w języku polskim UJ
Ten unikalny zestaw pełnotekstowych, elektronicznych wersji tekstów literackich w języku polskim (od początków piśmiennictwa polskiego do chwili obecnej) powstaje jako materiał do badań ilościowych nad językiem oryginałów i przekładów. Umożliwia połączenie badań leksykalnych i syntaktycznych z czytaniem na dystans, czyli połączenie stylometrii danych tekstowych ze statystyczną analizą metadanych (autor, tłumacz, rok pierwszego wydania oryginału, rok pierwszego wydania przekładu, język oryginału i in.). Istniejąca wersja prototypowa zawiera utwory w prostym formacie tekstowym (UTF-8); w przyszłości korpus będzie dostępny w formacie XML zgodnym z wytycznymi TEI, tak w całości, jak w dowolnym wyborze; teksty nie znajdujące się w domenie publicznej będą oczywiście dostępne wyłącznie jako frekwencje elementów językowych.
| Proza i poezja | Dramat | Razem | |
| Polskie oryginały | 4162 | 340 | 4502 |
| Polskie przekłady | 5068 | 432 | 5500 |
| Razem | 9230 | 772 | 10002 |
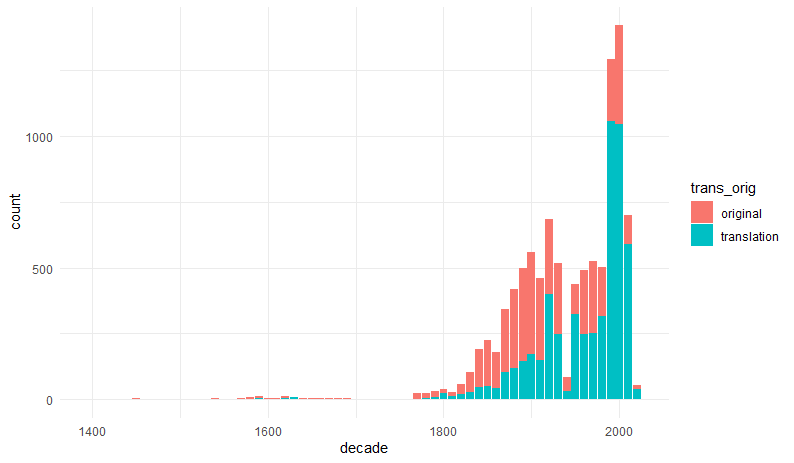
Rys. 1. Liczba oryginałów i przekładów dekadami.
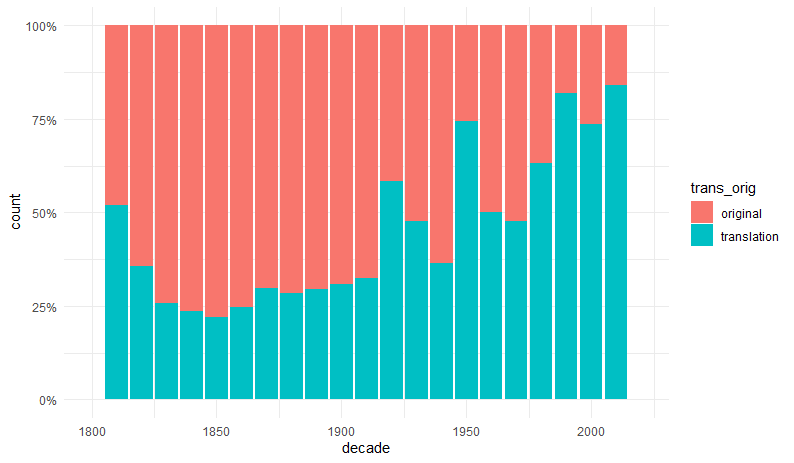
Rys. 2. Liczba oryginałów i przekładów dekadami od 1800 r.
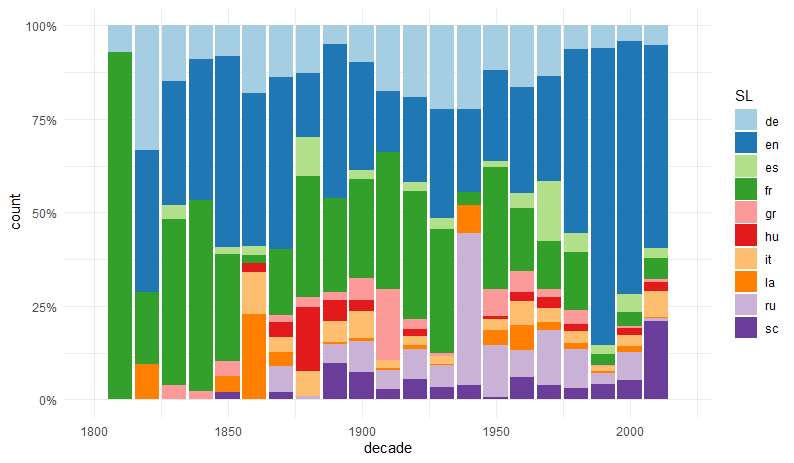
Rys. 3. Liczba przekładów z 10 najważniejszych języków dekadami od 1800 r.
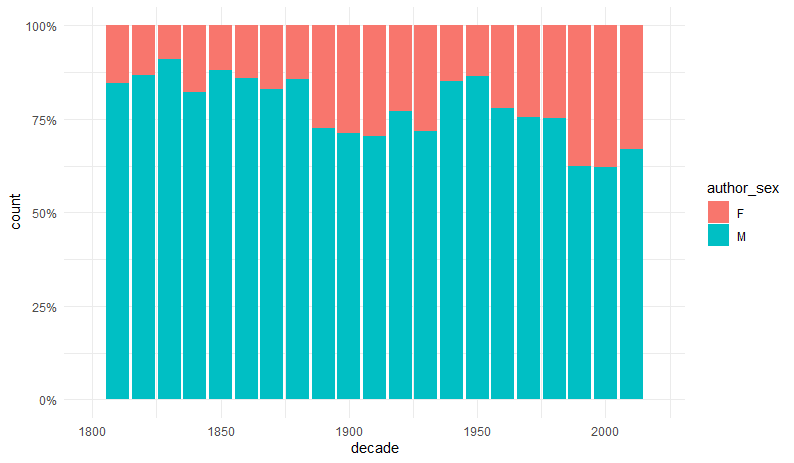
Rys. 4. Liczba polskich autorek i autorów dekadami od 1800 r.
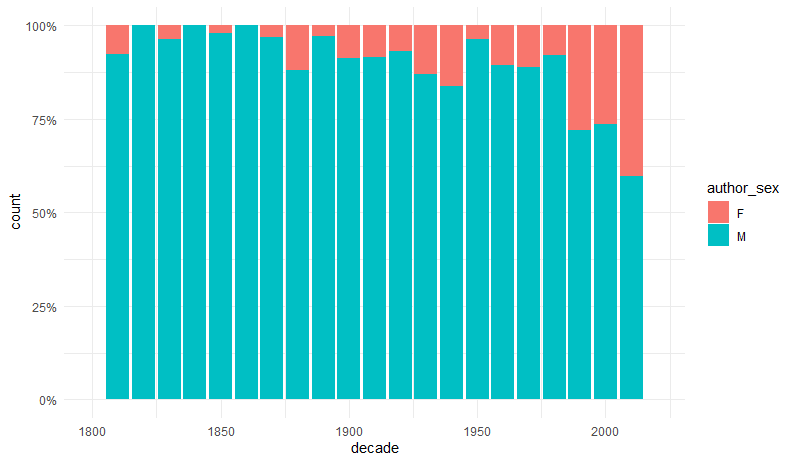
Rys. 5. Liczba obcych autorek i autorów dekadami od 1800 r.
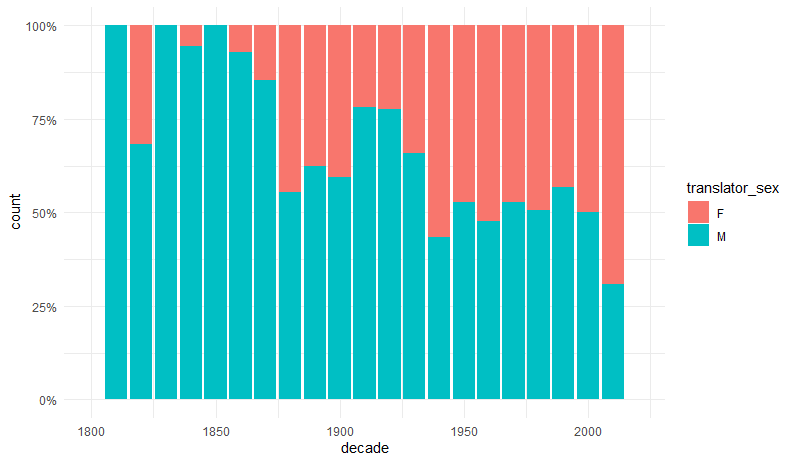
Rys. 6. Liczba tłumaczek i tłumaczy dekadami od 1800 r.